
![]()
Introduction
Anyone who knows me fairly well in my programming life will know that I’m not as partial to Java.
I’m a JavaScript developer first and foremost. It was what I learned first, it confounded then delighted me after I started to get the hang of it, and it made a heck of a lot more sense to me than Java, what with its compilation, its need to declare every single variable type (yes, I know the latest versions of Java have done away with this requirement for some of the simpler inferences), and its massive libraries of maps, lists, collections, etc.: HashMaps, Maps, HashTables, TreeMaps, ArrayLists, LinkedLists, Arrays, it goes on and on.
That being said, I do make an effort to get better at Java and the other shortcomings I have by not having a traditional computer science degree. If you’d like to know more about my atypical path to becoming a software engineer, you can read my very first blog post here.
So when I told a colleague of mine about a coding challenge I’d come across a couple months back and how I solved it (and then performance tested my various solutions) in JavaScript, he looked back at me and said: “How would you solve it using Java?”

I stared at him as the wheels began to turn in my head, and I accepted the challenge to find an optimal solution in Java, as well.
In this post, I’ll show you a variety of solutions (and their performance) to parse through really, really large datasets using the Java programming language.
The challenge I faced
So before I get down to how I solved my challenge using Java, let me actually recap the requirements.
In the original article I wrote on using Node.js to read really, really large files, this was a coding challenge issued to a developer for an insurance technology company.
The challenge was straightforward enough: download this large zip file of text from the Federal Elections Commission, read that data out of the .txt file supplied, and supply the following info:
- Write a program that will print out the total number of lines in the file.
- Notice that the 8th column contains a person’s name. Write a program that loads in this data and creates an array with all name strings. Print out the 432nd and 43243rd names.
- Notice that the 5th column contains a form of date. Count how many donations occurred in each month and print out the results.
- Notice that the 8th column contains a person’s name. Create an array with each first name. Identify the most common first name in the data and how many times it occurs.
Link to the data: https://www.fec.gov/files/bulk-downloads/2018/indiv18.zip*
NOTE: I add the asterisk after the file link because others who have chosen to undertake this challenge themselves have actually seen the file size increase since I downloaded it back in the beginning of October of 2018. At last count, someone mentioned it was up to 3.5GB now, so it seems as if this data is still live and being added to all the time. I believe the solutions I present below will still work though, but your counts and numbers will vary from mine.
I liked the challenge and wanted some practice manipulating files, so I decided to see if I could figure it out.
Now, without further ado, let’s talk about some different solutions I came up with to read really, really large files in Java.
The three Java-based solutions I came up with
Java has long been a standard programming language with file processing capabilities, and as such, there’s been a large number of ever improving ways to read, write and manipulate files with it.
Some methods are baked straight into the core Java framework, and some are still independent libraries that need to be imported and bundled together to run. But regardless, I came up with three different methods to read files in Java, and then I performance tested them to see which methods were more efficient.
Below are snippets of various pieces of code, if you’d like to see all of the original code, you can access my Github repo here.
You’ll notice that I used the same code logic to extract the data from each file, the major differences are between the initial file connection and text parsing. I did this so that I could have a more accurate idea of how the different methods stacked up against each other for the performance part of my evaluation. Apples to apples comparisons and all that.
Solution #1: Java FileInputStream() and Scanner() Implementation
The first solution I came up with uses Java’s built-in FileInputStream() method combined with Scanner().
In essence, FileInputStream just opens the connection to the file to be read, be it images, characters, etc. It doesn’t particularly care what the file actually is, because Java reads the input stream as raw bytes of data. Another option (at least for my case) is to use FileReader() which is specifically for reading streams of characters, but I went with FileInputStream() for this particular scenario. I used FileReader() in another solution I tested later on.
Once the connection to the file is established, Scanner comes into play to actually parse the text bytes into strings of readable data. Scanner() breaks its inputs into tokens using a delimiter pattern, which by default matches whitespace (but can also be overridden to use regex or other values). Then, by using the Scanner.hasNextLine() boolean, and the Scanner.nextLine() method, I can read the contents of the text file line by line and pull out the pieces of data that I need.
Scanner.nextLine() actually advances this scanner past the current line and returns the input that was skipped, which is how I’m able to gather the required info from each line until there’s no more lines to read and Scanner.hasNextLine() returns false and the while loop ends.
Here’s a sample of code using FileInputStream() and Scanner().
File f = new File("src/main/resources/config/test.txt");
try {
FileInputStream inputStream = new FileInputStream(f);
Scanner sc = new Scanner(inputStream, "UTF-8");
// do some things ...
while (sc.hasNextLine()) {
String line = sc.nextLine();
// do some more things ...
}
// do some final things
}And here is my full code to solve all the tasks laid out above.
NOTE: Click the title of any of these files to go to GitHub and see the full working code repo.
ReadFileJavaApplicationFileInputStream.java
package com.example.readFile.readFileJava;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.time.Duration;
import java.time.Instant;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Scanner;
public class ReadFileJavaApplicationFileInputStream {
public static void main(String[] args) throws IOException {
File f = new File(Common.getPathToTargetFile(args));
try {
FileInputStream inputStream = new FileInputStream(f);
Scanner sc = new Scanner(inputStream, "UTF-8");
// get total line count
Instant lineCountStart = Instant.now();
int lines = 0;
Instant namesStart = Instant.now();
ArrayList<String> names = new ArrayList<>();
// get the 432nd and 43243 names
ArrayList<Integer> indexes = new ArrayList<>();
indexes.add(1);
indexes.add(433);
indexes.add(43244);
// count the number of donations by month
Instant donationsStart = Instant.now();
ArrayList<String> dates = new ArrayList<>();
// count the occurrences of first name
Instant commonNameStart = Instant.now();
ArrayList<String> firstNames = new ArrayList<>();
System.out.println("Reading file using File Input Stream");
while (sc.hasNextLine()) {
String line = sc.nextLine();
lines++;
// get all the names
String array1[] = line.split("\\s*\\|\\s*");
String name = array1[7];
names.add(name);
if (indexes.contains(lines)) {
System.out.println("Name: " + names.get(lines - 1) + " at index: " + (lines - 1));
}
if (name.contains(", ")) {
String array2[] = (name.split(", "));
String firstHalfOfName = array2[1].trim();
if (!firstHalfOfName.isEmpty()) {
if (firstHalfOfName.contains(" ")) {
String array3[] = firstHalfOfName.split(" ");
String firstName = array3[0].trim();
firstNames.add(firstName);
} else {
firstNames.add(firstHalfOfName);
}
}
}
String rawDate = array1[4];
String month = rawDate.substring(4, 6);
String year = rawDate.substring(0, 4);
String formattedDate = month + "-" + year;
dates.add(formattedDate);
}
sc.close();
Instant namesEnd = Instant.now();
long timeElapsedNames = Duration.between(namesStart, namesEnd).toMillis();
System.out.println("Name time: " + timeElapsedNames + "ms");
System.out.println("Total file line count: " + lines);
Instant lineCountEnd = Instant.now();
long timeElapsedLineCount = Duration.between(lineCountStart, lineCountEnd).toMillis();
System.out.println("Line count time: " + timeElapsedLineCount + "ms");
HashMap<String, Integer> dateMap = new HashMap<>();
for (String date : dates) {
Integer count = dateMap.get(date);
if (count == null) {
dateMap.put(date, 1);
} else {
dateMap.put(date, count + 1);
}
}
for (Map.Entry<String, Integer> entry : dateMap.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("Donations per month and year: " + key + " and donation count: " + value);
}
Instant donationsEnd = Instant.now();
long timeElapsedDonations = Duration.between(donationsStart, donationsEnd).toMillis();
System.out.println("Donations time: " + timeElapsedDonations + "ms");
HashMap<String, Integer> map = new HashMap<>();
for (String name : firstNames) {
Integer count = map.get(name);
if (count == null) {
map.put(name, 1);
} else {
map.put(name, count + 1);
}
}
LinkedList<Entry<String, Integer>> list = new LinkedList<>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
public int compare(Map.Entry<String, Integer> o1,
Map.Entry<String, Integer> o2) {
return (o2.getValue()).compareTo(o1.getValue());
}
});
System.out.println("The most common first name is: " + list.get(0).getKey() + " and it occurs: " + list.get(0).getValue() + " times.");
Instant commonNameEnd = Instant.now();
long timeElapsedCommonName = Duration.between(commonNameStart, commonNameEnd).toMillis();
System.out.println("Most common name time: " + timeElapsedCommonName + "ms");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}After the file’s data is being read one line at a time, it’s simply a matter of getting the necessary data and manipulating it to fit my needs.
Task #1: Get the file’s total line count
Getting the line count for the entire file was easy. All that involved was a new int lines = 0 declared outside the while loop, which I incremented each time the loop ran again.
Request #1: done.
Task #2: Create a list of all the names and find the 432nd and 43243rd names
The second request, which was to collect all the names and print the 432nd and 43243rd names from the array, required me to create an ArrayList<String> names = new ArrayList<>(); and an ArrayList<Integers> indexes = new ArrayList<>(); which I promptly added the indexes of 432 and 43243 with indexes.add(433) and indexes.add(43244), respectively.
I had to add 1 to each index to get the correct name position in the array because I incremented my line count (starting at 0) as soon as Scanner.hasNextLine() returned true. After Scanner.nextLine() returned the previous line’s contents I could pull out the names I needed, which meant its true index (starting from index 0) was actually the index of the line count minus one. (Trust me, I triple checked this to make sure I was doing my math correctly).
I used an ArrayList for the names because it maintains the element’s insertion order which means while displaying ArrayList elements the result set will always have the same order in which the elements got inserted into the List. Since I’m iterating through the file line by line, the elements will always be inserted into the list in the same order.
Here’s the full logic I used to get all the names and then print out the names if the indexes I had in my indexes ArrayList matched the lines count index.
int lines = 0;
ArrayList<String> names = new ArrayList<>();
// get the 432nd and 43243 names
ArrayList<Integer> indexes = new ArrayList<>();
indexes.add(433);
indexes.add(43244);
System.out.println("Reading file using File Input Stream");
while (sc.hasNextLine()) {
String line = sc.nextLine();
lines++;
// get all the names
String array1[] = line.split("\\s*\\|\\s*");
String name = array1[7];
names.add(name);
if (indexes.contains(lines)) {
System.out.println("Name: " + names.get(lines - 1) + " at
index: " + (lines - 1));
}
// ...
}Request #2: done.
Task #3: Count how many donations occurred in each month
As I approached the donation counting request, I wanted to do more than count donations by month, I wanted to count them by both month and year, as I had donations from both 2017 and 2018.
The very first thing I did was set up an initial ArrayList to hold all my dates: ArrayList<String> dates = new ArrayList<>();.
Then, I took the 5th element in each line, the raw date, and used the substring() method to pull out just the month and year for each donation.
I reformatted each date into easier-to-read dates and added them to the new dates ArrayList.
String rawDate = array1[4];
String month = rawDate.substring(4, 6);
String year = rawDate.substring(0, 4);
String formattedDate = month + "-" + year;
dates.add(formattedDate);After I’d collected all the dates, I created a HashMap to hold my dates: HashMap<String, Integer> dateMap = new HashMap<>();, and then looped through the dates list to either add the dates as keys to the HashMap if they didn’t already exist or increment their value count, if they did exist.
Once the HashMap was made, I ran that new map through another for loop to get each object’s key and value to print out to the console. Voilà.
The date results were not sorted in any particular order, but they could be by transforming the HashMap back in to an ArrayList or LinkedList, if need be. I chose not to though, because it was not a requirement.
HashMap<String, Integer> dateMap = new HashMap<>();
for (String date : dates) {
Integer count = dateMap.get(date);
if (count == null) {
dateMap.put(date, 1);
} else {
dateMap.put(date, count + 1);
}
}
for (Map.Entry<String, Integer> entry : dateMap.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("Donations per month and year: " +
entry.getKey() + " and donation count: " + entry.getValue());
}Request #3: done.
Task #4: Identify the most common first name and how often it occurs
The fourth request, to get all the first names only and find the count of the most commonly occurring one, was trickiest.
It required me to first, check if the names array contained a comma (there were some business names that had no commas), then split() the name on the comma and trim() any extraneous white space from it.
Once that was cleaned up, I had to check if the first half of the name had any white spaces (meaning the person had a first name and middle name or possibly a moniker like “Ms.”) and if it did, split() it again, and trim() up the first element of the newly made array (which I presumed would almost always be the first name).
If the first half of the name didn’t have a space, it was added to the firstNames ArrayList as is. That’s how I collected all the first names from the file. See the code snippet below.
// count the occurrences of first name
ArrayList<String> firstNames = new ArrayList<>();
System.out.println("Reading file using File Input Stream");
while (sc.hasNextLine()) {
String line = sc.nextLine();
// get all the names
String array1[] = line.split("\\s*\\|\\s*");
String name = array1[7];
names.add(name);
if (name.contains(", ")) {
String array2[] = (name.split(", "));
String firstHalfOfName = array2[1].trim();
if (firstHalfOfName != undefined ||
!firstHalfOfName.isEmpty()) {
if (firstHalfOfName.contains(" ")) {
String array3[] = firstHalfOfName.split(" ");
String firstName = array3[0].trim();
firstNames.add(firstName);
} else {
firstNames.add(firstHalfOfName);
}
}
}Once I’ve collected all the first names I can, and the while loop reading the file has ended, it’s time to sort the names and find the most common one.
For this, I created another new HashMap: HashMap<String, Integer> map = new HashMap<>();, then looped through all the names and if the name didn’t exist in the map already, it was created as the map’s key and the value was set as 1. If the name already existed in the HashMap, the value was incremented by 1.
HashMap<String, Integer> map = new HashMap<>();
for (String name : firstNames) {
Integer count = map.get(name);
if (count == null) {
map.put(name, 1);
} else {
map.put(name, count + 1);
}
}But wait — there’s more! Once we have the HashMap, which is unordered by nature, it needs to be sorted from largest to smallest value to get the most commonly occurring first name, so I transform each entry in the HashMap into a LinkedList, which can be ordered and iterated through.
LinkedList<Entry<String, Integer>> list = new LinkedList<>(map.entrySet());And finally, the list is sorted using the Collections.sort() method, and invoking the Comparator interface to sort the name objects according to their value counts in descending order (highest value is first). Check this out.
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>()
{
public int compare(Map.Entry<String, Integer> o1,
Map.Entry<String, Integer> o2) {
return (o2.getValue()).compareTo(o1.getValue());
}
}
);Once all of that has been done, the first key value pair of the LinkedList can finally be pulled out and displayed to the user. Here’s the whole shebang that’s put together once the all the first names have been read out of the file.
HashMap<String, Integer> map = new HashMap<>();
for (String name : firstNames) {
Integer count = map.get(name);
if (count == null) {
map.put(name, 1);
} else {
map.put(name, count + 1);
}
}
LinkedList<Entry<String, Integer>> list = new LinkedList<>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>()
{
public int compare(Map.Entry<String, Integer> o1,
Map.Entry<String, Integer> o2) {
return (o2.getValue()).compareTo(o1.getValue());
}
}
);
System.out.println("The most common first name is: " + list.get(0).getKey() + " and it occurs: " + list.get(0).getValue() + " times.");Request #4 (and arguably the most complicated of all the tasks): done.
Great, now that I’ve given you the soliloquy of my brain’s logic in Java, I can give you much quicker overviews of the other two methods I tried for reading the text data from the files. (Because the logic portion of the code is exactly the same.)
Solution #2: Java BufferedReader() and FileReader() implementation
My second solution involved two more of Java’s core methods: BufferedReader() and FileReader().
BufferedReader reads text from a character-input stream, buffering characters so as to provide for the efficient reading of characters, arrays, and lines, and it is wrapped around the FileReader method, which is the actual method reading the specified text file. The BufferedReader makes the FileReader more efficient in its operation, that’s all.
BufferedReader’s method readLine() is what actually reads back each line of the text as it is read from the stream, allowing us to pull out the data needed.
The setup is similar to FileInputStream and Scanner; you can see how to implement BufferedReader and FileReader below.
File f = new File("src/main/resources/config/test.txt");
try (BufferedReader b = new BufferedReader(new FileReader(f))) {
String readLine = "";
// do some things ...
while ((readLine = b.readLine()) != null) {
// do some more things...
}
// do some final things
}And here is my full code using BufferedReader() and FileReader().
ReadFileJavaApplicationBufferedReader.java
package com.example.readFile.readFileJava;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.time.Duration;
import java.time.Instant;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.Map;
import java.util.Map.Entry;
public class ReadFileJavaApplicationBufferedReader {
public static void main(String[] args) {
try {
File f = new File(Common.getPathToTargetFile(args));
try (BufferedReader b = new BufferedReader(new FileReader(f))) {
String readLine = "";
// get total line count
Instant lineCountStart = Instant.now();
int lines = 0;
Instant namesStart = Instant.now();
ArrayList<String> names = new ArrayList<>();
// get the 432nd and 43243 names
ArrayList<Integer> indexes = new ArrayList<>();
indexes.add(1);
indexes.add(433);
indexes.add(43244);
// count the number of donations by month
Instant donationsStart = Instant.now();
ArrayList<String> dates = new ArrayList<>();
// count the occurrences of first name
Instant commonNameStart = Instant.now();
ArrayList<String> firstNames = new ArrayList<>();
System.out.println("Reading file using Buffered Reader");
while ((readLine = b.readLine()) != null) {
lines++;
// get all the names
String array1[] = readLine.split("\\s*\\|\\s*");
String name = array1[7];
names.add(name);
if(indexes.contains(lines)){
System.out.println("Name: " + names.get(lines - 1) + " at index: " + (lines - 1));
}
if(name.contains(", ")) {
String array2[] = (name.split(", "));
String firstHalfOfName = array2[1].trim();
if (!firstHalfOfName.isEmpty()) {
if (firstHalfOfName.contains(" ")) {
String array3[] = firstHalfOfName.split(" ");
String firstName = array3[0].trim();
firstNames.add(firstName);
} else {
firstNames.add(firstHalfOfName);
}
}
}
String rawDate = array1[4];
String month = rawDate.substring(4,6);
String year = rawDate.substring(0,4);
String formattedDate = month + "-" + year;
dates.add(formattedDate);
}
Instant namesEnd = Instant.now();
long timeElapsedNames = Duration.between(namesStart, namesEnd).toMillis();
System.out.println("Name time: " + timeElapsedNames + "ms");
System.out.println("Total file line count: " + lines);
Instant lineCountEnd = Instant.now();
long timeElapsedLineCount = Duration.between(lineCountStart, lineCountEnd).toMillis();
System.out.println("Line count time: " + timeElapsedLineCount + "ms");
HashMap<String, Integer> dateMap = new HashMap<>();
for(String date:dates){
Integer count = dateMap.get(date);
if (count == null) {
dateMap.put(date, 1);
} else {
dateMap.put(date, count + 1);
}
}
for (Map.Entry<String, Integer> entry : dateMap.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("Donations per month and year: " + key + " and donation count: " + value);
}
Instant donationsEnd = Instant.now();
long timeElapsedDonations = Duration.between(donationsStart, donationsEnd).toMillis();
System.out.println("Donations time: " + timeElapsedDonations + "ms");
HashMap<String, Integer> map = new HashMap<>();
for(String name:firstNames){
Integer count = map.get(name);
if (count == null) {
map.put(name, 1);
} else {
map.put(name, count + 1);
}
}
LinkedList<Entry<String, Integer>> list = new LinkedList<>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer> >() {
public int compare(Map.Entry<String, Integer> o1,
Map.Entry<String, Integer> o2)
{
return (o2.getValue()).compareTo(o1.getValue());
}
});
System.out.println("The most common first name is: " + list.get(0).getKey() + " and it occurs: " + list.get(0).getValue() + " times.");
Instant commonNameEnd = Instant.now();
long timeElapsedCommonName = Duration.between(commonNameStart, commonNameEnd).toMillis();
System.out.println("Most common name time: " + timeElapsedCommonName + "ms");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}Besides the BufferedReader and FileReader implementation, though, all the logic within is the same, so I’ll move on now to my final Java file reader implementation: FileUtils.LineIterator.
Apache Commons IO FileUtils.LineIterator() Implementation

The last solution I came up with involves a library made by Apache, called FileUtils.LineIterator(). It’s easy enough to include the dependency. I used Gradle for my Java project, so all I had to do was include the commons-io library in my build.gradle file.
dependencies {
compile group: 'commons-io', name: 'commons-io', version: '2.6'
}The LineIterator, does exactly what its name suggests: it holds a reference to an open Reader (like FileReader in my last solution), and iterates over each line in the file. And it’s really easy to set up LineIterator in the first place.
LineIterator has a built-in method called nextLine(), which actually returns the next line in the wrapped reader (not unlike Scanner’s nextLine() method or BufferedReader’s readLine() method).
Here’s the code to set up FileUtils.LineIterator() once the dependency library has been included.
File f = new File("src/main/resources/config/test.txt");
try {
LineIterator it = FileUtils.lineIterator(f, "UTF-8");
// do some things ...
while (it.hasNext()) {
String line = it.nextLine();
// do some other things ...
}
// do some final things
}And here is my full code using FileUtils.LineIterator().
ReadFileJavaApplicationLineIterator.java
package com.example.readFile.readFileJava;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.LineIterator;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.time.Duration;
import java.time.Instant;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.Map;
import java.util.Map.Entry;
public class ReadFileJavaApplicationLineIterator {
public static void main(String[] args) throws IOException {
File f = new File(Common.getPathToTargetFile(args));
try {
LineIterator it = FileUtils.lineIterator(f, "UTF-8");
// get total line count
Instant lineCountStart = Instant.now();
int lines = 0;
Instant namesStart = Instant.now();
ArrayList<String> names = new ArrayList<>();
// get the 432nd and 43243 names
ArrayList<Integer> indexes = new ArrayList<>();
indexes.add(1);
indexes.add(433);
indexes.add(43244);
// count the number of donations by month
Instant donationsStart = Instant.now();
ArrayList<String> dates = new ArrayList<>();
// count the occurrences of first name
Instant commonNameStart = Instant.now();
ArrayList<String> firstNames = new ArrayList<>();
System.out.println("Reading file using Line Iterator");
while (it.hasNext()) {
String line = it.nextLine();
lines++;
// get all the names
String array1[] = line.split("\\s*\\|\\s*");
String name = array1[7];
names.add(name);
if (indexes.contains(lines)) {
System.out.println("Name: " + names.get(lines - 1) + " at index: " + (lines - 1));
}
if (name.contains(", ")) {
String array2[] = (name.split(", "));
String firstHalfOfName = array2[1].trim();
if (!firstHalfOfName.isEmpty()) {
if (firstHalfOfName.contains(" ")) {
String array3[] = firstHalfOfName.split(" ");
String firstName = array3[0].trim();
firstNames.add(firstName);
} else {
firstNames.add(firstHalfOfName);
}
}
}
String rawDate = array1[4];
String month = rawDate.substring(4, 6);
String year = rawDate.substring(0, 4);
String formattedDate = month + "-" + year;
dates.add(formattedDate);
}
Instant namesEnd = Instant.now();
long timeElapsedNames = Duration.between(namesStart, namesEnd).toMillis();
System.out.println("Name time: " + timeElapsedNames + "ms");
System.out.println("Total file line count: " + lines);
Instant lineCountEnd = Instant.now();
long timeElapsedLineCount = Duration.between(lineCountStart, lineCountEnd).toMillis();
System.out.println("Line count time: " + timeElapsedLineCount + "ms");
HashMap<String, Integer> dateMap = new HashMap<>();
for (String date : dates) {
Integer count = dateMap.get(date);
if (count == null) {
dateMap.put(date, 1);
} else {
dateMap.put(date, count + 1);
}
}
for (Map.Entry<String, Integer> entry : dateMap.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("Donations per month and year: " + key + " and donation count: " + value);
}
Instant donationsEnd = Instant.now();
long timeElapsedDonations = Duration.between(donationsStart, donationsEnd).toMillis();
System.out.println("Donations time: " + timeElapsedDonations + "ms");
HashMap<String, Integer> map = new HashMap<>();
for (String name : firstNames) {
Integer count = map.get(name);
if (count == null) {
map.put(name, 1);
} else {
map.put(name, count + 1);
}
}
LinkedList<Entry<String, Integer>> list = new LinkedList<>(map.entrySet());
Collections.sort(list, new Comparator<Entry<String, Integer>>() {
public int compare(Map.Entry<String, Integer> o1,
Map.Entry<String, Integer> o2) {
return (o2.getValue()).compareTo(o1.getValue());
}
});
System.out.println("The most common first name is: " + list.get(0).getKey() + " and it occurs: " + list.get(0).getValue() + " times.");
Instant commonNameEnd = Instant.now();
long timeElapsedCommonName = Duration.between(commonNameStart, commonNameEnd).toMillis();
System.out.println("Most common name time: " + timeElapsedCommonName + "ms");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}NOTE: There is one thing you need to be aware of if you’re running a plain Java application without the aid of Spring Boot. If you want to use this extra Apache dependency library you need to manually bundle it together with your application’s JAR file into what’s called a fat JAR.
A fat jar (also known as an uber jar) is a self-sufficient archive which contains both classes and dependencies needed to run an application.
Spring Boot “automagically” bundles all of our dependencies together for us, but it’s also got a lot of extra overhead and functionalities that are totally unnecessary for this project, which is why I chose not to use it. It makes the project unnecessarily heavy.
There are plugins available now, but I just wanted a quick and easy way to bundle my one dependency up with my JAR. So I modified the jar task from the Java Gradle plugin. By default, this task produces jars without any dependencies.
I can overwrite this behavior by adding a few lines of code. I just need two things to make it work:
- A
Main-Classattribute in the manifest file (check, I had three main class files in my demo repo for testing purposes), - And any dependencies jars.
Thanks to Baeldung for the help on making this fat JAR.
jar {
manifest {
attributes "Main-Class": "com.example.readFile.readFileJava.ReadFileJavaApplicationLineIterator"
}
from {
configurations.compile.collect {
it.isDirectory() ? it : zipTree(it)
}
}
}Once the main class file has been defined (and in my demo repo, I made three main class files, which confused my IDE to no end) and the dependencies were included, you can run the ./gradlew assemble command from the terminal and then:
java -cp ./build/libs/readFileJava-0.0.1-SNAPSHOT.jar com.example.readFile.readFileJava.ReadFileJavaApplicationLineIteratorAnd your program should run with the LineIterator library included.
If you’re using IntelliJ as your IDE, you can also just use its run configurations locally with each of the main files specified as the correct main class, and it should run the three programs as well. See my README.md for more info on this.
Great, now I have three different ways to read and process large text files in Java, my next mission: figure out which way is more performant.
How I evaluated the solution’s performance and their results
For performance testing my different Java applications and the functions inside them, I came across two handy, ready-made functions in Java 8: Instant.now() and Duration.between().
What I wanted to do was see if there was any measurable differences between the different ways of reading the same file. So besides the different file read options: FileInputStream, BufferedReader and LineIterator, I tried to keep the code (and timestamps marking the start and stop of each function) as similar as possible. And I think it worked out pretty well.
Instant.now() does exactly what its name suggests: it holds a single, instantaneous point on the timeline, stored as a long representing epoch-seconds and an int representing a nanosecond-of-seconds. This isn’t incredibly useful all on it’s own, but when it’s combined with Duration.between(), it becomes very useful.
Duration.between() takes a start interval and an end interval and finds the duration between those two times. That’s it. And that timing can be converted to all sorts of different, readable formats: milliseconds, seconds, minutes, hours, etc.
Here’s an example of implementing Instant.now() and Duration.between() in my files. This one is timing how long it takes to get the line count of the total file.
try {
LineIterator it = FileUtils.lineIterator(f, "UTF-8");
// get total line count
Instant lineCountStart = Instant.now();
int lines = 0;
System.out.println("Reading file using Line Iterator");
while (it.hasNext()) {
String line = it.nextLine();
lines++;
}
System.out.println("Total file line count: " + lines);
Instant lineCountEnd = Instant.now();
long timeElapsedLineCount =
Duration.between(lineCountStart, lineCountEnd).toMillis();
System.out.println("Line count time: " +
timeElapsedLineCount + "ms");
} Results
Here’s the results after applying Instant.now() and Duration.between() to all of my different file read methods in Java.
I ran all three of my solutions against the 2.55GB file, which contained just over 13 million lines in total.

As you can see from the table, BufferedReader() and LineIterator() both fared well, but they’re so close in their timings it seems to be up to the developer which they’d rather use.
BufferedReader() is nice because it requires no extra dependencies, but it is slightly more complex to set up in the beginning, with the FileReader() to wrap inside. Whereas LineIterator() is an external library but it makes iterating over the file extra easy after it is included as a dependency.
The percentage improvements are included at the end of the table above as well, for reference.
FileInputStream, in an interesting twist, got blown out of the water by the other two. By buffering the data stream or using the library made specifically for iterating through text files, performance improved by about 73% on all tasks.
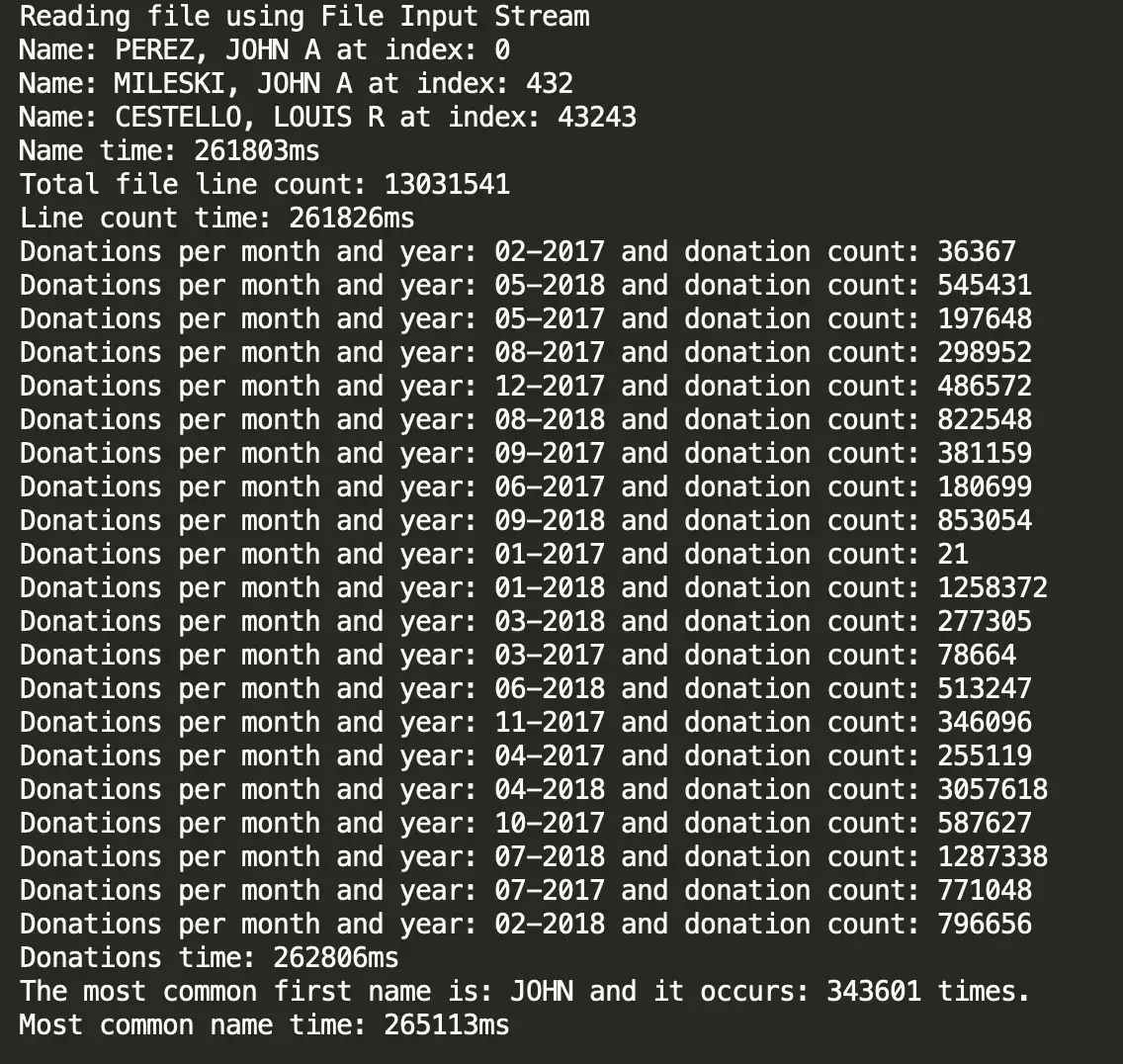
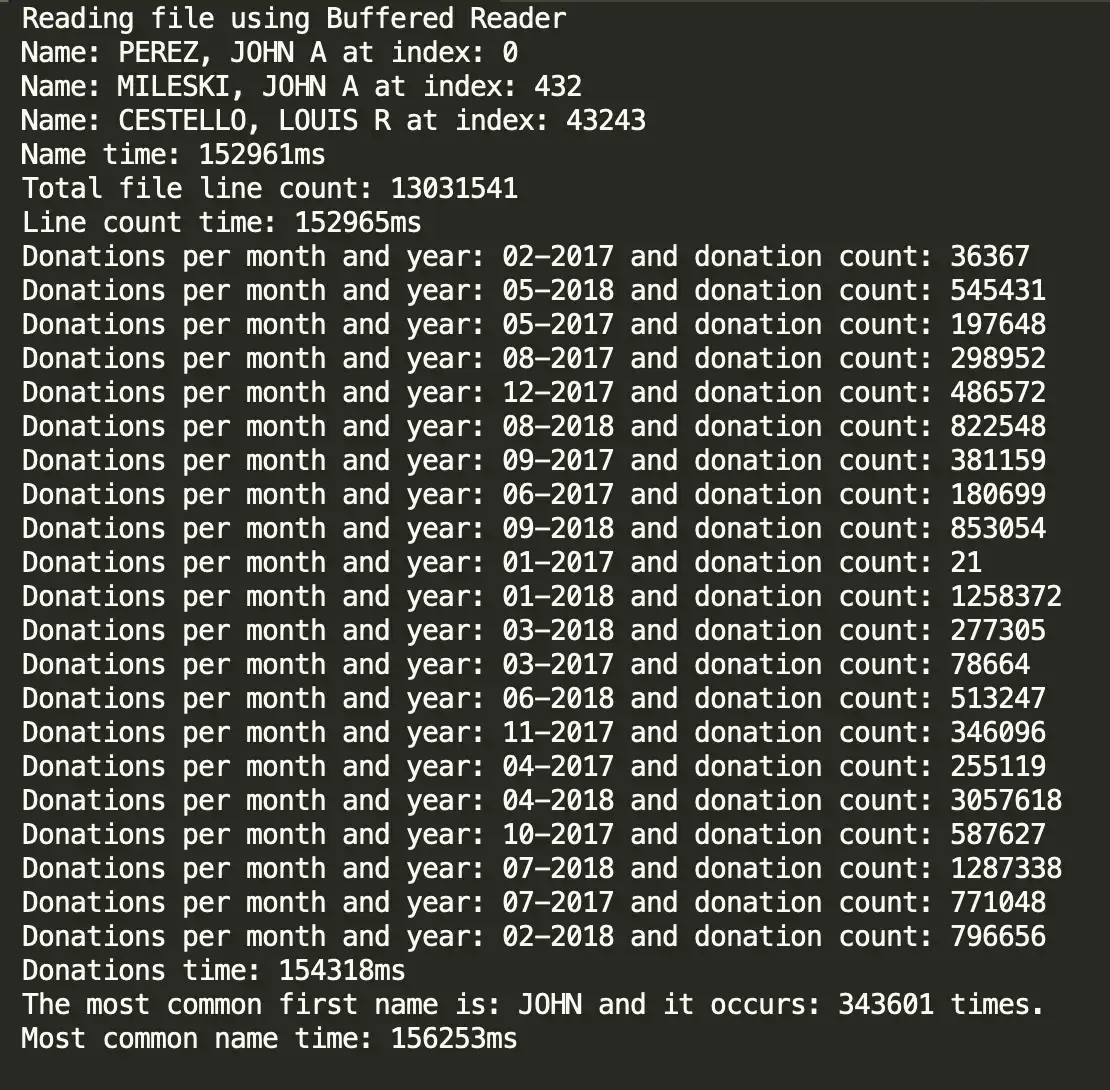
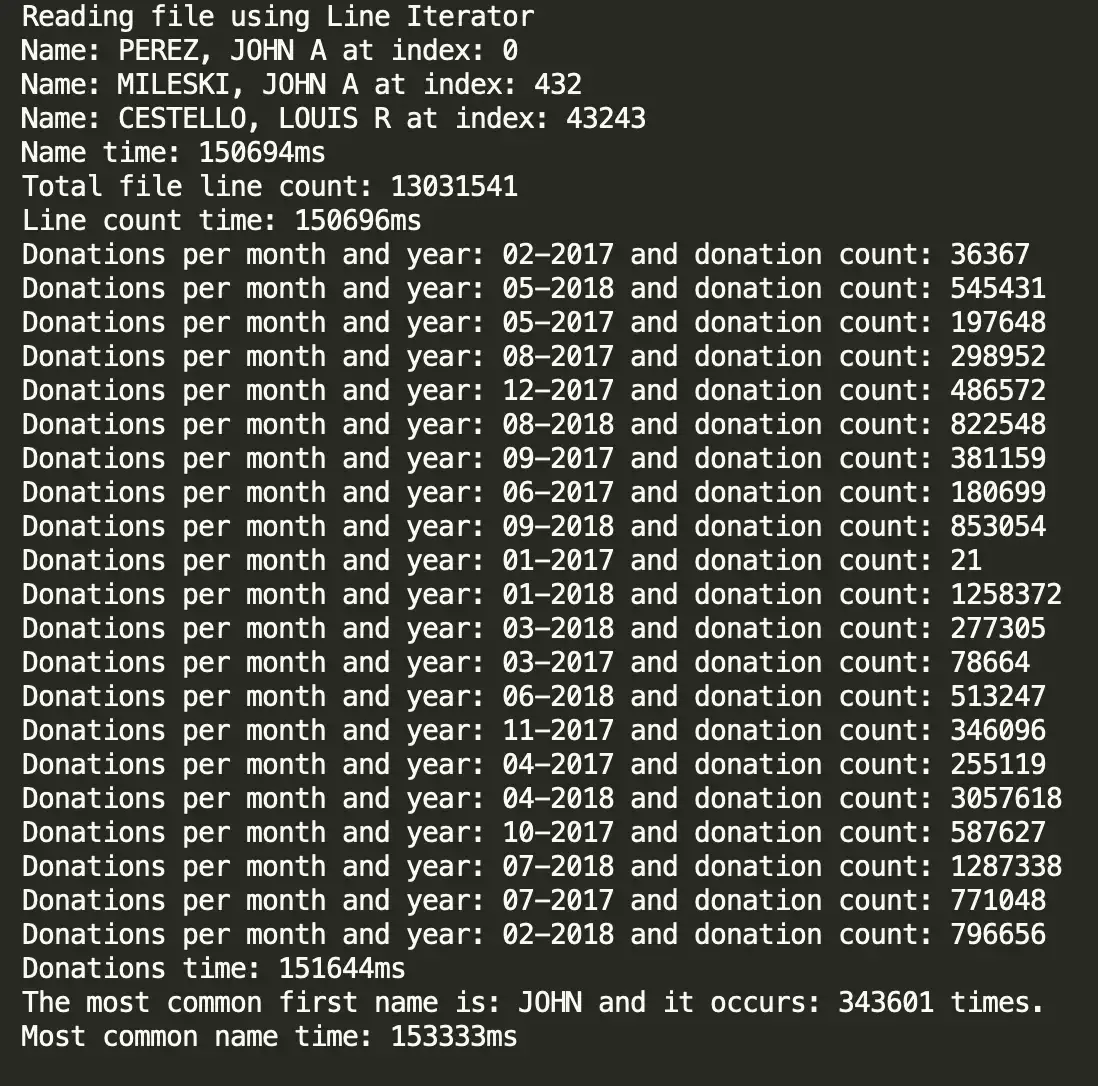
Below are the raw screenshots from my terminal for each of my solutions.
Solution #1: FileInputStream()
Solution #2: BufferedReader()
Solution #3: FileUtils.lineIterator()
Conclusion
In the end, buffered streams and custom file read libraries are the most efficient ways processing large data sets in Java. At least, for the large text files I was tasked with reading.
Thanks for reading my post on using Java to read really, really large files. If you’d like to see the original posts on Node.js that inspired this one, you can see part 1 and part 2.
Check back in a few weeks, I’ll be writing about Swagger with Express.js or something else related to web development and JavaScript, so subscribe to my newsletter so you don’t miss out.
Thanks for reading, I hope this gives you an idea of how to handle large amounts of data with Java efficiently and performance test your solutions.
References & Further Resources
- Github, Read File in Java Repo
- Link to the FEC data
- Oracle Java Documentation, FileInputStream
- Oracle Java Documentation, Scanner
- Oracle Java Documentation, BufferedReader
- Oracle Java Documentation, FileReader
- Apache Commons Java Documentation, LineIterator
- Baeldung, Creating a Fat Jar in Gradle
- Oracle Java Documentation, Instant
- Oracle Java Documentation, Duration